Last week I was at the Engage user group event in the Netherlands. Theo Heselmans and team put together people, sessions and entertainment for over 400 attendees and this year (by my count of hands) nearly 30% were attending for the first time. There are only a few IRL (in real life) conferences I can manage to get to each year and I’m always pleased by what I get out of them, but this year’s Engage was for me the best event for several years primarily because of contributions from HCL and all their news about what they have been working on. Oh, and the location! Theo always manages to choose a special location and the Burgers’ Zoo conference center in Arnhem that had us walking through a rainforest with the sound of birds each day was certainly that.
This guy walked me in on the first day, giving me side-eye pretty much the whole way.
The only thing that confused me was the milk that was put out for the tea and coffee. I’ve never seen milk of that color before and since we were in a zoo there was a debate about the animal that produced it. Maybe Giraffe…?
On the closing night Theo organized a trip to a pub/brewery in Arnhem called Taphuis for us speakers. They had over 100 beers and a contactless card you tapped as you poured out your choice. I’m not a big beer drinker but I “tapped” a lot of 5cl tastes and then came up with the not very smart idea of everyone choosing a beer that matched their age. Let’s just say it worked out for some better than for others.
An idea that I think really worked was having an open speaker’s area where people could gather and catch up with each other, with other attendees and with HCL. I had several informal meetings there and having no doors encouraged everyone to come and take a seat. The unlimited Belgian chocolate and waffles didn’t hurt either.
So, at this point, with major updates to Domino, Connections, Sametime and new products like Nomad for mobile, the question for me was: Where are HCL taking things next? The theme for the conference was “Evolve” and although I didn’t get to attend as many sessions as I would have liked, there were lots of “a-ha” moments for me where the work I’d been hearing about for a year suddenly clicked into place as solutions for customers.
I could write a lot more on what I came away excited about, but these are my highlights.
Sametime
Let’s start with Sametime. The biggest issue since v9 of Sametime (we’re now on v10) was the IBM-driven design that was dependent on the WebSphere and DB2 architectures. I do a lot of Sametime installs and a clustered environment would be in the region of 30 individual server elements. When HCL bought Sametime and asked for feedback on what we all wanted the biggest request was to simplify the install and get rid of WebSphere. Since then, HCL have released v10 and v11 of Sametime, which were primarily the Community (chat) servers and new web and mobile clients, so this time at Engage we got to see and hear about the v11 Sametime Meetings due in the next few months.
Sametime v11 already has user-side integration with any conferencing provider, but Sametime Meetings will now be delivered as a single Docker container (instead of nearly 20 servers) with everything needed to deliver its own meetings, audio, video and screen sharing in one single install. The entire architecture for Meetings has been replaced with open source servers, removal of java, and a fast, lightweight browser client. The focus for v11 has been ease of use for clients and simplification for administrators and it looks like they are delivering.
If you’re interested in the new Sametime v11 mobile clients, you can register for the beta here.
Domino
As development continues on Domino, including making it the backbone for many of the other products, it was tremendous news to hear that they are now extending the investment in its function as a mail server. The news that Domino continues to be updated and enhanced, such as adding 2-factor authentication for both web and Notes clients in v12, is what many of us had been hoping to hear from HCL. For on-premise customers, Domino continues to be the only strategic mail solution and the only one currently being extended.
HCL Nomad Web
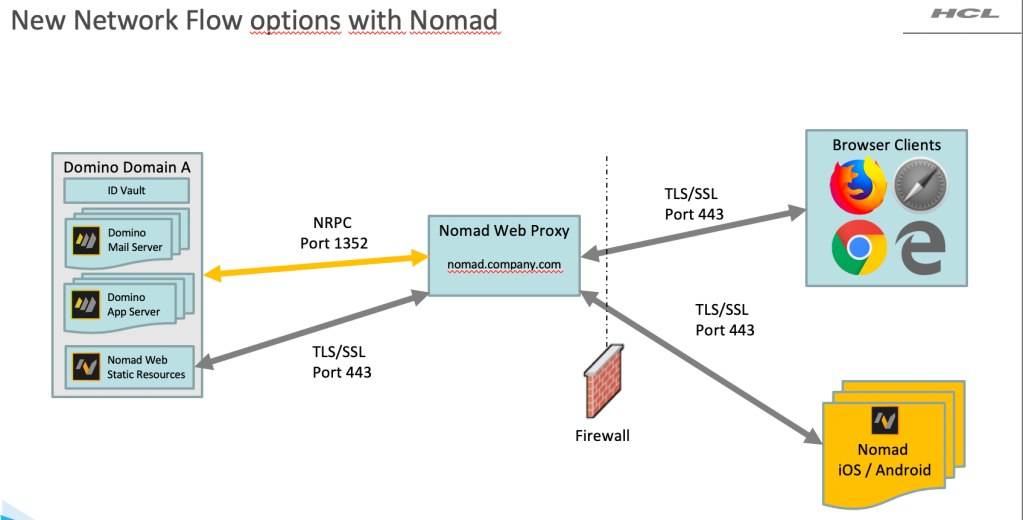
Hopefully you already know about and are using Nomad for mobile, available for iOS, iPadOS and (as of last week) Android. The Nomad brand delivers the Notes client experience through a mobile OS allowing you to access your existing Notes applications on your Domino servers without installing any server-side software or making any programming changes. The next Nomad product is Nomad Web which is truly a new option as a Notes client. It’s not a replacement client but it will be a go-to for many people who want to access Notes applications without managing a client infrastructure.
Nomad Web is based on browser technology so it will work on any operating system (Windows, Linux , Mac) that can run any standard browser, giving you a “Notes client” with a small install footprint (they are aiming at less than 100mb) and running anywhere. This is all very exciting; it looks like a Notes client, it doesn’t require a client install, it can run on multiple platforms, and since there is no server-side installation it will work against older versions of Domino as well as current.
That’s innovation, offering an easy-to-maintain-and-deploy client as an option to both existing and new customers. HCL Nomad Web will be going into public beta in the next couple of months.
Domino Volt
Volt is a Domino-based, visual, low-code development environment that is delivered through a browser. What does that actually mean? I attended a workshop at Engage to learn how to develop an application using Volt because I’m absolutely not a developer and so consider myself a good test case. After logging in to the Domino server I can click to create a form, drag and drop to position all kinds of fields, images and text, and even click for simple workflow. It provides a way for anyone to create simple applications that can be extended for more complex work by a developer who can still use all the Domino programming tools, integration, and reporting technologies.
The introduction of an entirely new development tool aimed at non-developers and delivered through any standard browser is really interesting and I recommend attending the upcoming webinar as well as signing up for the Volt beta that is now publicly available. Working with the beta allows you to feed back to HCL on what features you think might be missing and to contribute into getting the product right.
Register for the Domino Volt beta here.
Register for the Domino Volt webinar here.
If you go to the Engage site, you can already download many of the presentations. It’s not the same as being there in person, but there’s a ton of valuable content even for those of us who didn’t get to as many sessions as we wanted.
Looking forward to Engage 2021 already!