It’s now been several weeks since HCL took full ownership of what were the ICS (IBM Collaboration Solutions) products that include Domino, Sametime, Notes, Verse, Traveler, Portal and Connections. In those few weeks there’s been a lot of activity, not least transitioning over the development and support teams and setting up new systems for support, software access and community news.
You’ve probably seen many of the announcements or even attended the multiple webcasts but here are a few in case you missed them.
The new HCL division that holds responsiblity for these products is called Digital Solutions and their homepage for all HCL DS (not sure they use that abbreviation) activity is here https://www.cwpcollaboration.com. The blog you will want to follow is at https://www.cwpcollaboration.com/blogs.
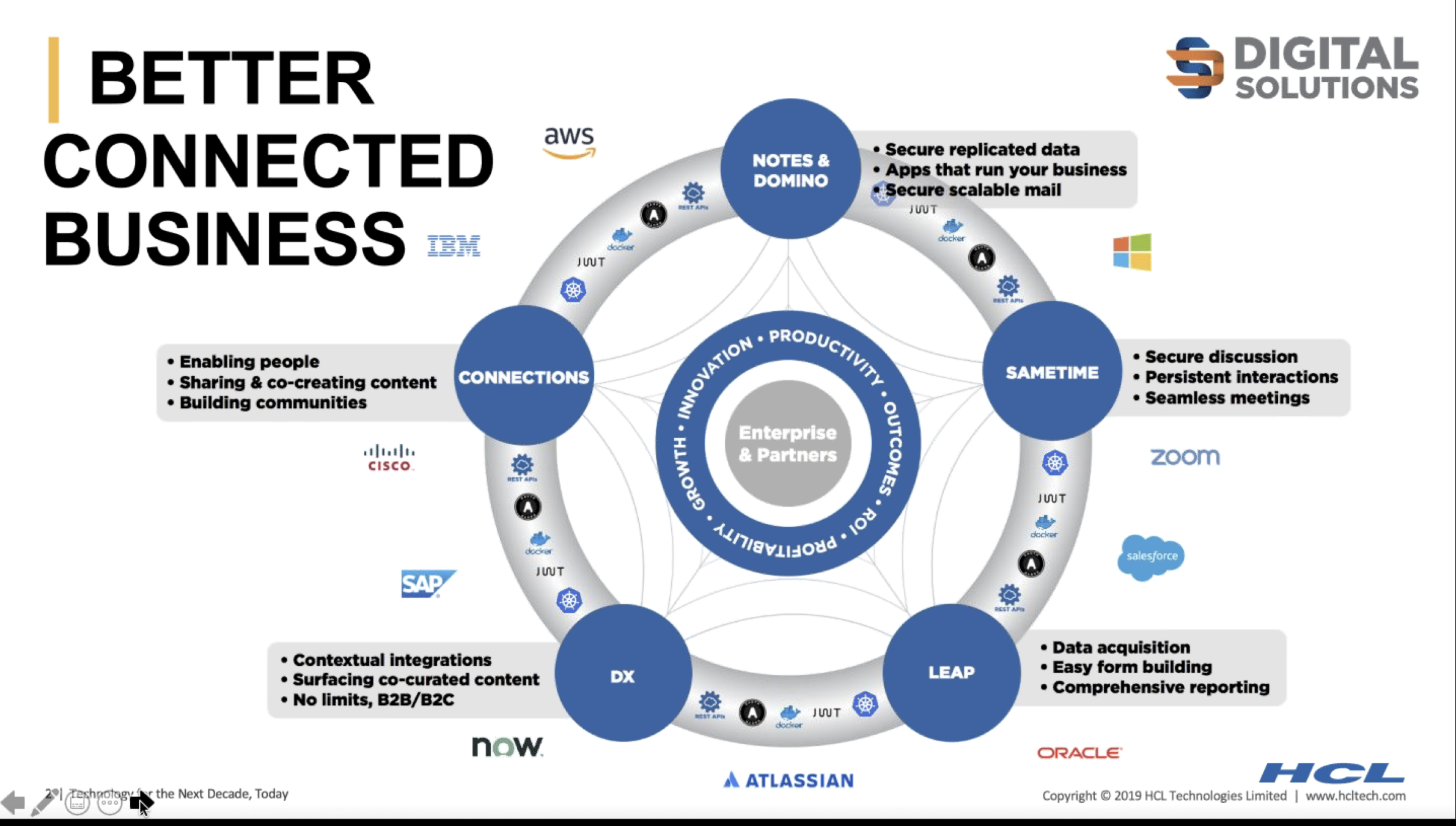
So what does HCL Digital Solutions look like?
Along with the owernship of Notes/Domino, Sametime, Connections, LEAP (previously FEB), you can see all the planned integration points including Rest APIs, docker, Zoom, Salesforce and more. The Digital Solutions story is one that connects all their products together and understands the importance of other applications and services to the whole.
If you’re an existing customer you are going to want to register for both a customer account and a support account. Right now HCL don’t have single sign-on across their sites so you do need to register an account for each service. I’m not saying you “should” but you “could” use the same login and password everywhere.
To register as a customer go here
To register for support go here
To register for your software licenses and downloads (which HCL will have been given a record of by IBM) go here
HCL have also announced the first drop of the v11 beta which will be for Notes (Windows and Mac), Domino (Windows and Linux), Designer (Windows) and the embedded Sametime client. All of these in English language strings only on Sept 16th.
To register for the first beta drop you must sign up here by September 16th, after that date you will be added to the test group for the second beta drop https://registration.hclpartnerconnect.com/D11Beta
If you are interested in licensing, that has also transitioned to HCL entirely. Although I know of a few customers receiving letters from IBM, they are no longer entitled to sell your renewal or additional licenses. If you have any questions about licensing reach out to your Business Partner or visit the eCommerce portal online (you’ll need to register as a customer first) https://buy.hcltechsw.com
HCL have also committed to delivering v12 of the products in Q4 2020 so we are on schedule for one major release (and interim smaller releases) a year with v11 due in Q4 2019.
If the idea of upgrading all your clients it a bit overwhelming, don’t forget you have an entitlement to use Panagenda’s MarvelClient Essentials to upgrade from v9 at no charge. MarvelClient Essentials is built into Notes 10.0.1 and later but you can download it here if you need to get to that point.
So the question is, have you deployed v10 yet ?