IBM Docs is a really nice add on to IBM Connections, what’s more it’s not particularly hard to install. It does have one requirement, a big one, a show stopping one, a requirement that prevented my customer build from working for about four weeks until IBM and I came up with an agreement for how it could work. Hopefully this will help you fast forward through that four weeks yourself ..
IBM Docs Infrastructure - The Simple Version
IBM Docs has four component WebSphere servers with applications stored on each
The servers also need access to three data shares; the standard Connections share, a new share for IBM Docs data and a new share for IBM Docs Viewer. I created the two new shared on the Linux server that currently hosted the CIFS Connections share and installed Samba to enable a Windows server to access them.
I had one problem where it consistently failed during install if I didn’t use capital letters for the mapped drives. It didn’t refuse to accept lower case letters, it just failed the install. If your install fails make sure you aren’t using lower case letters.
Challenges
The key requirement for IBM Docs to actually work is that
1. The shares must use mapped drive letters and those drives letters must exist prior to the IBM Docs elements being started
2. The IBM recommendation for achieving this is to create a batch file on the IBM Docs OS (which must be partially if not wholly Windows) to do the drive mapping and have that load in Windows task scheduler on startup.
3. The WAS servers must then be run as services not using a system account but using a named Windows account that matches the one assigned to run the batch file in task scheduler
This solution had two problems, I hated it, and it didn’t work.
I hated this idea because my customer doesn’t run AD at all and their share was a samba share on a Linux box using CIFS. That means there is no account that can be used to start the services that can also be used to map the drives. There is no easy way to have Windows pass credentials to mount the shares without storing both the name and password that samba recognises in the batch file - like this
net use m: \\hubshared\ibmdocsdata sambapassword /user:sambaaccount
net use n: \\hubshared\ibmdocsview sambapassword /user:sambaaccount
net use l: \\hubshared\conntestshare sambapassword /user:sambaaccount
Unfortunately after several weeks of different ideas from L3 support we admitted defeat to allow me to move on with the install. I have minimised risk by ensuring the account isn’t a linux account and only has access to the samba shares.
The second part of the solution is the assumption that if you map the drives through task scheduler owned by a Windows user and that same Windows user starts the WAS services - the WAS services will be able to see the mapped drives. To everyone’s disappointment that absolutely didn’t work because Microsoft kindly mapped the drives from the batch file in a different session to the one where it started the WAS services. The servers couldn’t see the mapped drives.
So the install was simple but getting everything running securely and without the customer having to manually do anything held us up for weeks. In the end I opted for a solution where I created a batch file to both map the drives and then start the WAS servers in a scheduled startup script. That worked beautifully and this is what it looks like
net use m: \\hubshared\ibmdocsdata sambapassword /user:sambaaccount
net use n: \\hubshared\ibmdocsview sambapassword /user:sambaaccount
net use l: \\hubshared\conntestshare sambapassword /user:sambaaccount
Call “c:\IBM\WebSphere\AppServer\profiles\IBMDocs\bin\startnode”
Call “c:\IBM\WebSphere\AppServer\profiles\IBMConversion\bin\startnode”
Call “c:\IBM\WebSphere\AppServer\profiles\IBMViewer\bin\startnode”
Call “c:\IBM\WebSphere\AppServer\profiles\IBMDocsProxy\bin\startnode”
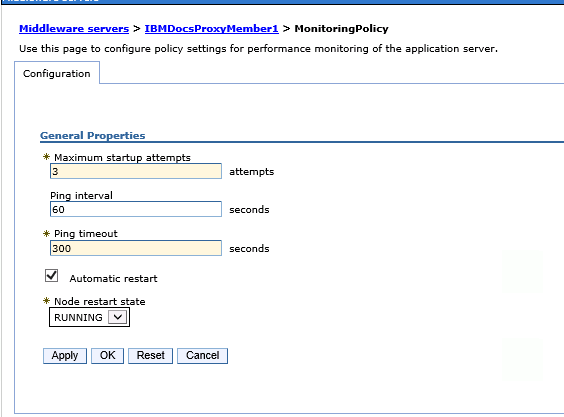
As you can see I only start the nodeagents. The servers themselves and the applications on them are bootstrapped to the start of those. To do that modify the server’s monitoring policy which is found under Java and Process Management for each server
Then set the “Node Restart State” to “RUNNING”